July 2, 2012, midnight by Rosalind Team
Topics: Combinatorics
Transcription May Begin Anywhere
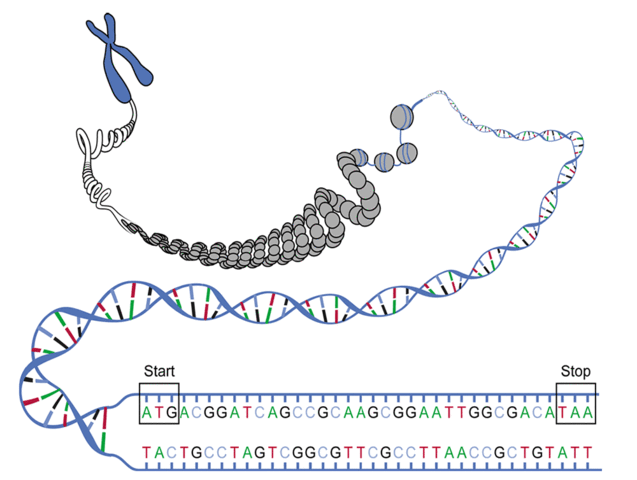
Figure 1. Schematic image of the particular ORF with start and stop codons shown.In “Transcribing DNA into RNA”, we discussed the transcription of DNA into RNA, and in “Translating RNA into Protein”, we examined the translation of RNA into a chain of amino acids for the construction of proteins. We can view these two processes as a single step in which we directly translate a DNA string into a protein string, thus calling for a DNA codon table.
However, three immediate wrinkles of complexity arise when we try to pass directly from DNA to proteins. First, not all DNA will be transcribed into RNA: so-called junk DNA appears to have no practical purpose for cellular function. Second, we can begin translation at any position along a strand of RNA, meaning that any substring of a DNA string can serve as a template for translation, as long as it begins with a start codon, ends with a stop codon, and has no other stop codons in the middle. See Figure 1. As a result, the same RNA string can actually be translated in three different ways, depending on how we group triplets of symbols into codons. For example, ...AUGCUGAC... can be translated as ...AUGCUG..., ...UGCUGA..., and ...GCUGAC..., which will typically produce wildly different protein strings.
Either strand of a DNA double helix can serve as the coding strand for RNA transcription. Hence, a given DNA string implies six total reading frames, or ways in which the same region of DNA can be translated into amino acids: three reading frames result from reading the string itself, whereas three more result from reading its reverse complement.
An open reading frame (ORF) is one which starts from the start codon and ends by stop codon, without any other stop codons in between. Thus, a candidate protein string is derived by translating an open reading frame into amino acids until a stop codon is reached.
Given: A DNA string
Return: Every distinct candidate protein string that can be translated from ORFs of
>Rosalind_99 AGCCATGTAGCTAACTCAGGTTACATGGGGATGACCCCGCGACTTGGATTAGAGTCTCTTTTGGAATAAGCCTGAATGATCCGAGTAGCATCTCAG
MLLGSFRLIPKETLIQVAGSSPCNLS M MGMTPRLGLESLLE MTPRLGLESLLE