Dec. 4, 2012, 7:05 a.m. by Rosalind Team
Topics: Alignment
Certain Point Mutations are More Common
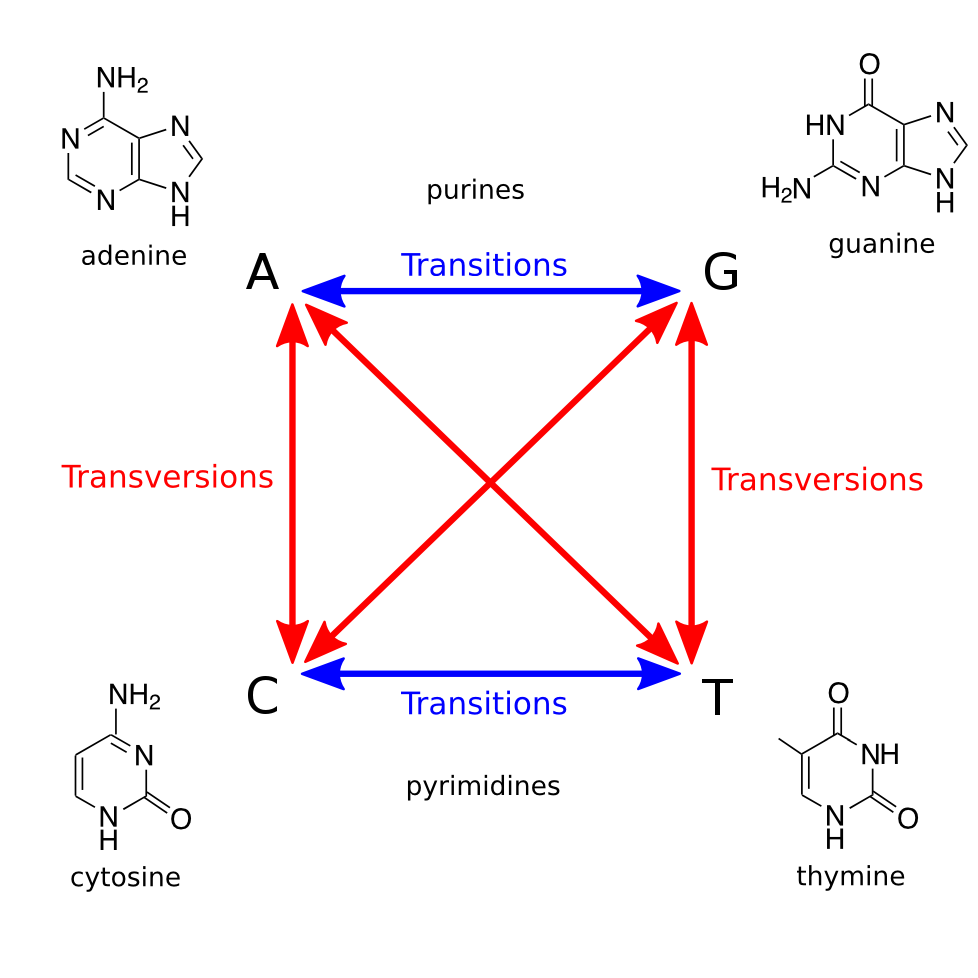
Figure 1. Illustration of transitions and transversions.Point mutations occurring in DNA can be divided into two types: transitions and transversions. A transition substitutes one purine for another (
$\textrm{A} \leftrightarrow \textrm{G}$ ) or one pyrimidine for another ($\textrm{C} \leftrightarrow \textrm{T}$ ); that is, a transition does not change the structure of the nucleobase. Conversely, a transversion is the interchange of a purine for a pyrimidine base, or vice-versa. See Figure 1. Transitions and transversions can be defined analogously for RNA mutations.Because transversions require a more drastic change to the base's chemical structure, they are less common than transitions. Across the entire genome, the ratio of transitions to transversions is on average about 2. However, in coding regions, this ratio is typically higher (often exceeding 3) because a transition appearing in coding regions happens to be less likely to change the encoded amino acid, particularly when the substituted base is the third member of a codon (feel free to verify this fact using the DNA codon table). Such a substitution, in which the organism's protein makeup is unaffected, is known as a silent substitution.
Because of its potential for identifying coding DNA, the ratio of transitions to transversions between two strands of DNA offers a quick and useful statistic for analyzing genomes.
For DNA strings
Given: Two DNA strings
Return: The transition/transversion ratio
>Rosalind_0209 GCAACGCACAACGAAAACCCTTAGGGACTGGATTATTTCGTGATCGTTGTAGTTATTGGA AGTACGGGCATCAACCCAGTT >Rosalind_2200 TTATCTGACAAAGAAAGCCGTCAACGGCTGGATAATTTCGCGATCGTGCTGGTTACTGGC GGTACGAGTGTTCCTTTGGGT
1.21428571429
{kind=link}