Feb. 3, 2013, 9:54 p.m. by Rosalind Team
Topics: Bioinformatics Tools, Sequence Analysis
The Genetic Code
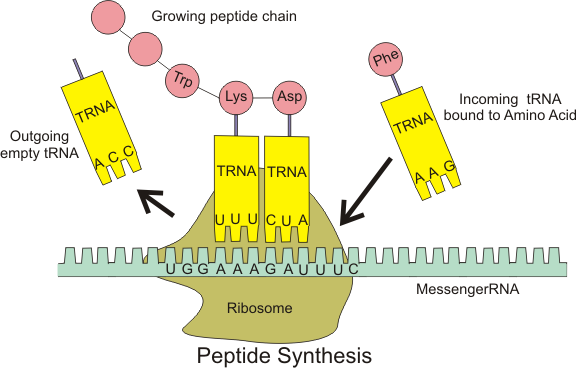
Figure 1. Schematic image of the translation process.Given a nucleotide sequence obtained from sequencing or a database, we want to know whether this sequence corresponds to a coding region of the genome. If so, you need only apply the genetic code to translate your sequence into an amino acid chain.
The apparent difficulty of translation is that somehow 4 RNA bases must correspond to a protein language of 20 amino acids; in order for every possible amino acid to be used, we must translate 3-nucleotide codons into amino acids (see Figure 1). Note that there are
$4^3 = 64$ possible codons, so that multiple codons may encode the same amino acid. Two special types of codons are the start codon (AUG), which codes for the amino acid methionine and always indicates the start of translation, and the three stop codons (UAA, UAG, UGA), which do not code for an amino acid and terminate the translation process.It is important to note that some organisms and DNA-containing organelles use an alternative form of the genetic code. This phenomenon is called genetic code variation. For example, vertebrate mitochondria treat AGA and AGG as stop codons instead of having these two codons code for arginine.
Thus, it is important to check the source of your genome data prior to translation.
The 20 commonly occurring amino acids are abbreviated by using 20 letters from the English alphabet (all letters except for B, J, O, U, X, and Z). Protein strings are constructed from these 20 symbols. The RNA codon table shows the encoding from each RNA codon to the amino acid alphabet.
The Translate tool from the SMS 2 package can be found here in the SMS 2 package
A detailed list of genetic code variants (codon tables) along with indexes representing these codes (1 = standard genetic code, etc.) can be obtained here.
For now, when translating DNA and RNA strings, we will start with the first letter of the string and ignore stop codons.
Given: A DNA string
Return: The index of the genetic code variant that was used for translation. (If multiple solutions exist, you may return any one.)
ATGGCCATGGCGCCCAGAACTGAGATCAATAGTACCCGTATTAACGGGTGA MAMAPRTEINSTRING
1
Programming Shortcut
BioPython possesses a
translate()method for converting RNA strings to protein strings:
translate(sequence, table='Standard', stop_symbol='*', to_stop=False)The
translate()method has the following parameters:
sequence: the DNA or RNA string to translate.table: the codon table to use. This can be either a name (string) or NCBI identifier (integer). Defaults to the "Standard" table, which has a value of 1.stop_symbol: a single symbol used to mark any terminators, which defaults to the asterisk "*".to_stop: a Boolean value. IfTrue, translation is terminated at the first stop codon appearing in the frame; defaults toFalse.Here are some examples of
translate()in action:>>> from Bio.Seq import translate >>> coding_dna = "GTGGCCATTGTAATGGGCCGCTGAAAGGGTGCCCGATAG" >>> translate(coding_dna) 'VAIVMGR*KGAR*' >>> translate(coding_dna, stop_symbol="@") 'VAIVMGR@KGAR@' >>> translate(coding_dna, to_stop=True) 'VAIVMGR' >>> translate(coding_dna, table=2) 'VAIVMGRWKGAR*' >>> translate(coding_dna, table=2, to_stop=True) 'VAIVMGRWKGAR'
{kind=link}