Connectivity in undirected graphs is pretty straightforward: a graph that is not connected can be decomposed in a natural and obvious manner into several connected components. Depth-first search does this handily, with each restart marking a new connected component.
In directed graphs, connectivity is more subtle. In some primitive sense, the directed
graph of the following graph is “connected”—it can’t be “pulled apart,” so to speak, without breaking
edges. But this notion is hardly interesting or informative. The graph cannot be considered
connected, because for instance there is no path from
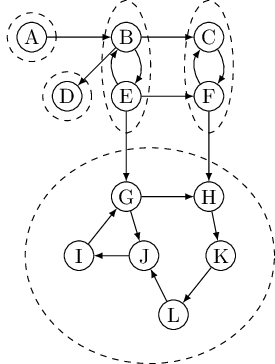
The right way to define connectivity for directed graphs is this: Two nodes
Now shrink each strongly connected component down to a single meta-node, and draw an edge from one meta-node to another if there is an edge (in the same direction) between their respective components. The resulting meta-graph must be a dag. The reason is simple: a cycle containing several strongly connected components would merge them all into a single, strongly connected component. Restated,
Property Every directed graph is a dag of its strongly connected components.
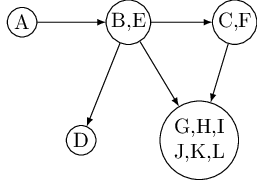
This tells us something important: The connectivity structure of a directed graph is two-tiered. At the top level we have a dag, which is a rather simple structure—for instance, it can be linearized. If we want finer detail, we can look inside one of the nodes of this dag and examine the full-fledged strongly connected component within.
The decomposition of a directed graph into its strongly connected components is very informative and useful. It turns out, fortunately, that it can be found in linear time by making further use of depth-first search. The algorithm is based on some properties we have already seen but which we will now pinpoint more closely.
Property 1 If the
Therefore, if we call
This suggests a way of finding one strongly connected component, but still leaves open two major problems: (A) how do we find a node that we know for sure lies in a sink strongly connected component and (B) how do we continue once this first component has been discovered?
Let’s start with problem (A). There is not an easy, direct way to pick out a node that is guaranteed to lie in a sink strongly connected component. But there is a way to get a node in a source strongly connected component.
Property 2 The node that receives the highest
This follows from the following more general property.
Property 3 If
Proof. In proving Property 3, there are two cases to consider. If the depth-first search visits
component
Property 3 can be restated as saying that the strongly connected components can be
linearized by arranging them in decreasing order of their highest
Property 2 helps us find a node in the source strongly connected component of
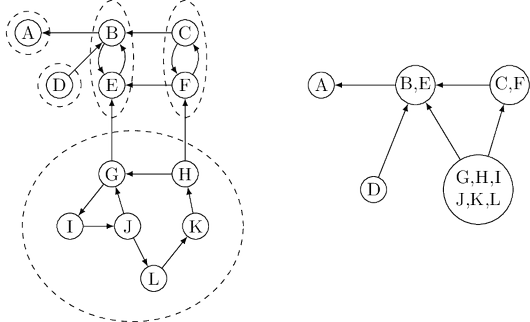
Onward to problem (B). How do we continue after the first sink component is identified?
The solution is also provided by Property 3. Once we have found the first strongly connected
component and deleted it from the graph, the node with the highest
This algorithm is linear-time, only the constant in the linear term is about twice that of
straight depth-first search. (Question: How does one construct an adjacency list representation
of
Source: Algorithms by Dasgupta, Papadimitriou, Vazirani. McGraw-Hill. 2006.