April 17, 2013, 5:54 p.m. by Rosalind Team
Topics: Bioinformatics Tools, Sequence Analysis
The Second Strand
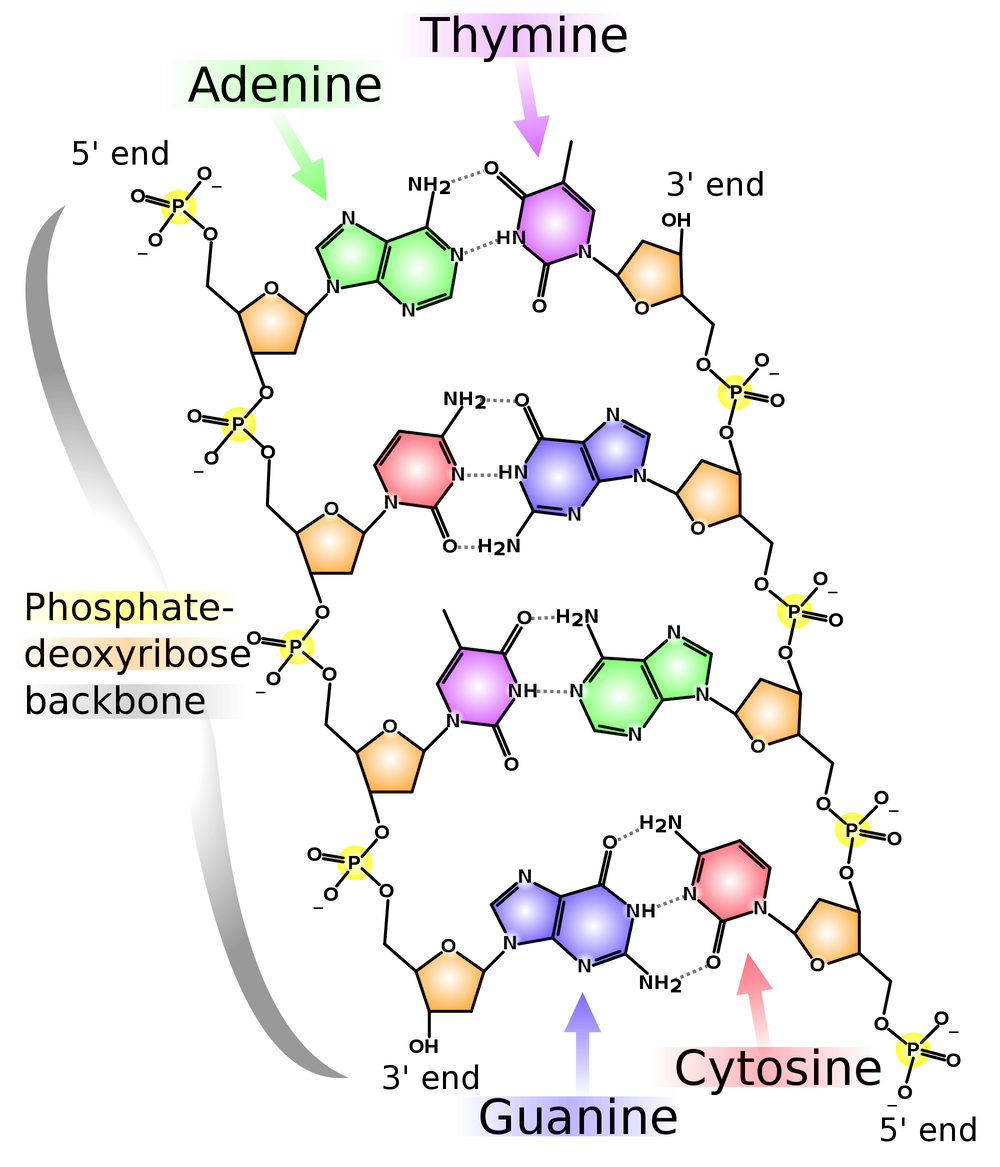
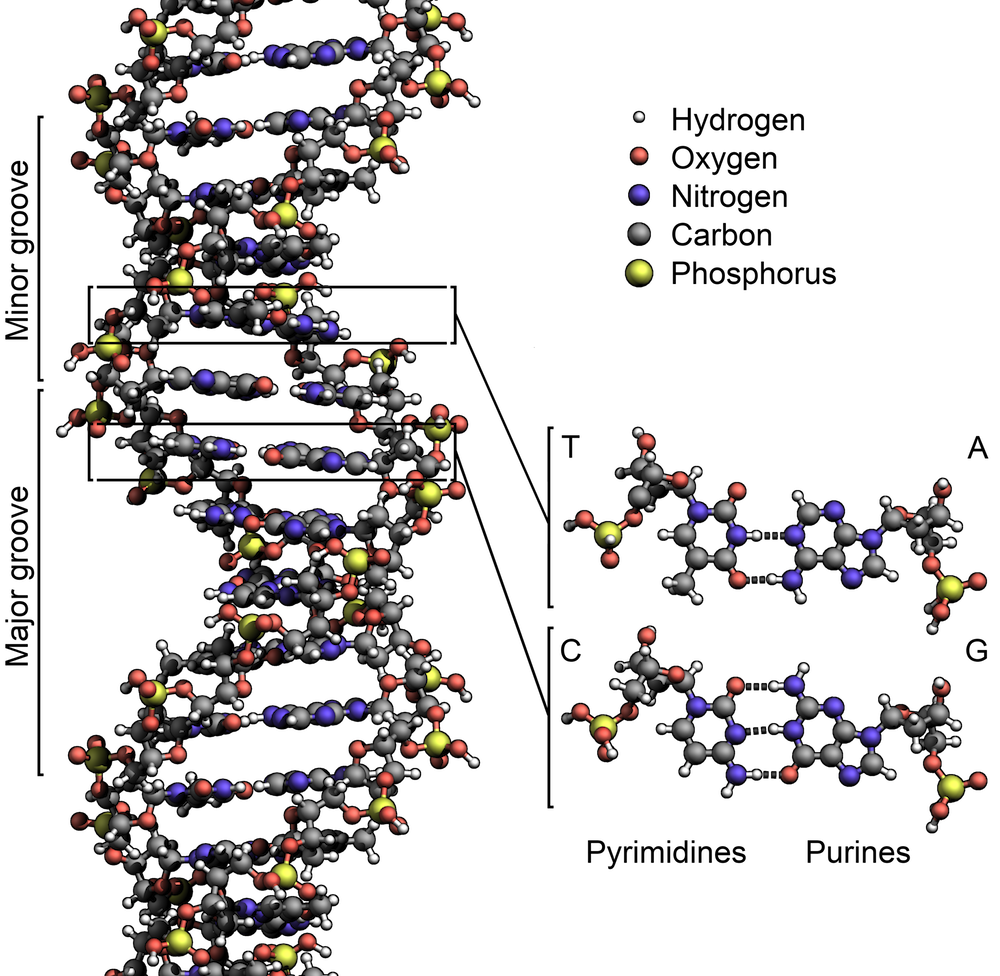
Figure 1. Base pairing across the two strands of DNA.Figure 2. The double helix of DNA on the molecular scale.Recall Watson and Crick's discovery of the following secondary structure for DNA that was introduced in “Counting DNA Nucleotides”:
- The DNA molecule is made up of two strands, running in opposite directions.
- Each base bonds to a base in the opposite strand. Adenine always bonds with thymine, and cytosine always bonds with guanine; the complement of a base is the base to which it always bonds; see Figure 1.
- The two strands are twisted together into a long spiral staircase structure called a double helix; see Figure 2.
Because genomic DNA is double-stranded, during sequence analysis we should examine both the given DNA string and its reverse complement.
A number of online tools exist for taking the reverse complement of a given DNA string. Like the
Reverse Complementprogram listed below, therevseqprogram from the EMBOSS package also performs this function. It can be run online here.
Recall that in a DNA string
The Reverse Complement program from the SMS 2 package can be run online here.
Given: A collection of
Return: The number of given strings that match their reverse complements.
>Rosalind_64 ATAT >Rosalind_48 GCATA
1
Programming Shortcut
BioPython can also be used to take the reverse complement of a DNA string locally. Specifically, the
complement()andreverse_complement()functions are suitable for this problem. These methods are associated with theSeqobject.>>> from Bio.Seq import Seq >>> from Bio.Alphabet import IUPAC >>> my_seq = Seq("GATCGATGGGCCTATATAGGATCGAAAATCGC", IUPAC.unambiguous_dna) >>> my_seq Seq('GATCGATGGGCCTATATAGGATCGAAAATCGC', IUPACUnambiguousDNA()) >>> my_seq.complement() Seq('CTAGCTACCCGGATATATCCTAGCTTTTAGCG', IUPACUnambiguousDNA()) >>> my_seq.reverse_complement() Seq('GCGATTTTCGATCCTATATAGGCCCATCGATC', IUPACUnambiguousDNA())The
IUPAC.unambiguous_dna()argument specifies that we are using the alphabet {A, C, G, T} and are not including the additional ambiguity symbols provided by IUPAC notation.