July 2, 2012, midnight by Rosalind Team
Topics: String Algorithms
The Secondary and Tertiary Structures of DNA
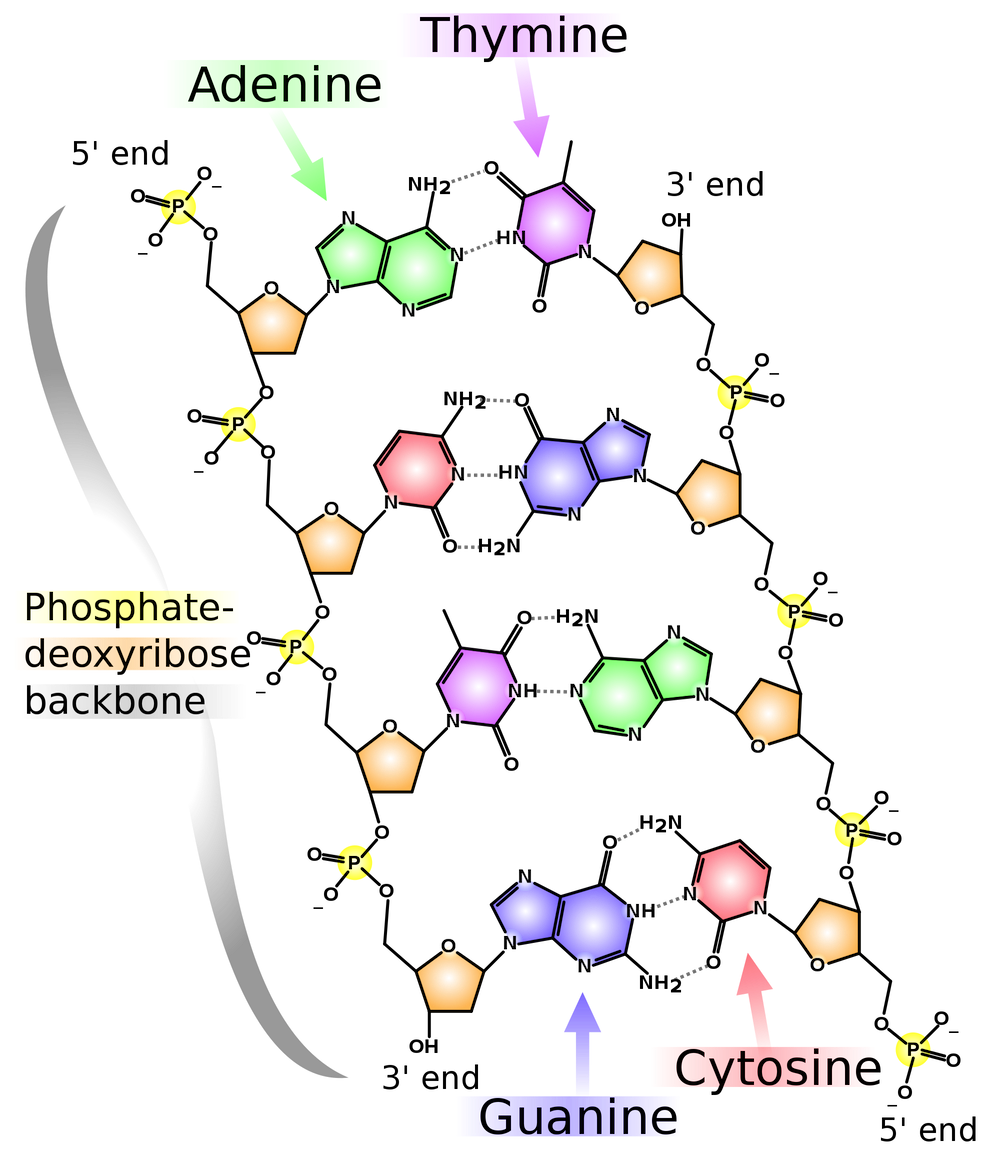
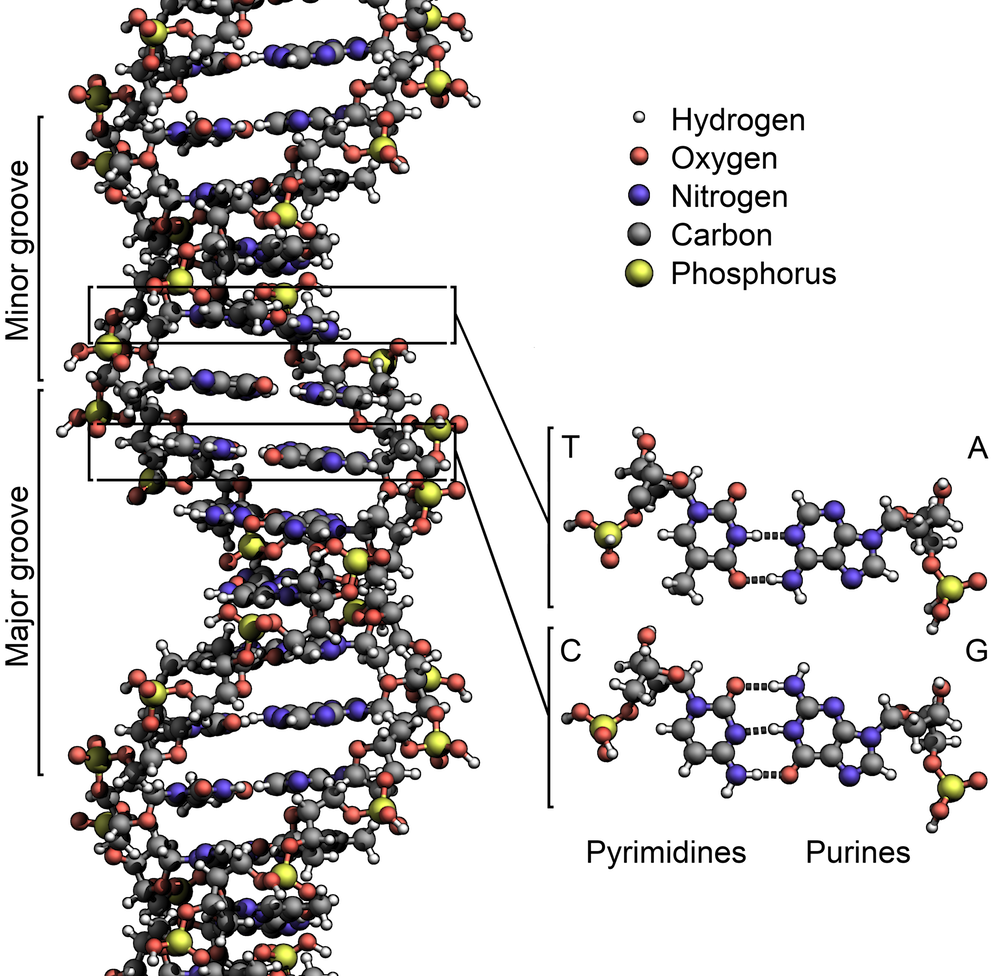
Figure 1. Base pairing across the two strands of DNA.Figure 2. The double helix of DNA on the molecular scale.In “Counting DNA Nucleotides”, we introduced nucleic acids, and we saw that the primary structure of a nucleic acid is determined by the ordering of its nucleobases along the sugar-phosphate backbone that constitutes the bonds of the nucleic acid polymer. Yet primary structure tells us nothing about the larger, 3-dimensional shape of the molecule, which is vital for a complete understanding of nucleic acids.
The search for a complete chemical structure of nucleic acids was central to molecular biology research in the mid-20th Century, culminating in 1953 with a publication in Nature of fewer than 800 words by James Watson and Francis Crick. Consolidating a high resolution X-ray image created by Rosalind Franklin and Raymond Gosling with a number of established chemical results, Watson and Crick proposed the following structure for DNA:
- The DNA molecule is made up of two strands, running in opposite directions.
- Each base bonds to a base in the opposite strand. Adenine always bonds with thymine, and cytosine always bonds with guanine; the complement of a base is the base to which it always bonds; see Figure 1.
- The two strands are twisted together into a long spiral staircase structure called a double helix; see Figure 2.
Because they dictate how bases from different strands interact with each other, (1) and (2) above compose the secondary structure of DNA. (3) describes the 3-dimensional shape of the DNA molecule, or its tertiary structure.
In light of Watson and Crick's model, the bonding of two complementary bases is called a base pair (bp). Therefore, the length of a DNA molecule will commonly be given in bp instead of nt. By complementarity, once we know the order of bases on one strand, we can immediately deduce the sequence of bases in the complementary strand. These bases will run in the opposite order to match the fact that the two strands of DNA run in opposite directions.
In DNA strings, symbols 'A' and 'T' are complements of each other, as are 'C' and 'G'.
The reverse complement of a DNA string
Given: A DNA string
Return: The reverse complement
AAAACCCGGT
ACCGGGTTTT