May 11, 2013, 10:36 a.m. by Rosalind Team
Topics: Bioinformatics Tools, Sequence Analysis
Classifying Open Reading Frames
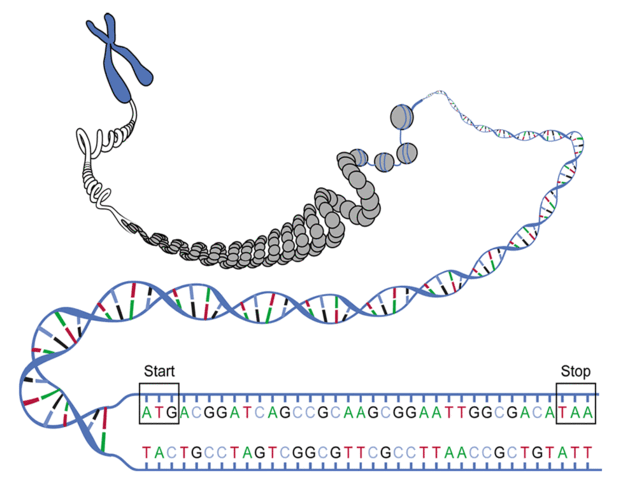
Figure 1. The reading frame in the top strand starting with ATG and ending with the stop codon TAA is an ORF.One of the first steps toward identifying possible genes in a piece of DNA is to search for an open reading frame (ORF), or an interval of DNA that can serve as a template for translation. An ORF is a reading frame that begins with a start codon, ends with either a stop codon or the end of the strand, and has no other stop codons in between (see Figure 1).
Recall that there are six reading frames for any strand of DNA: three derive from shifting translation of the strand itself (we can begin parsing codons at the first, second or third nucleotide) and three derive from shifts to the complementary strand. Both strands are counted because either strand of DNA can serve as the coding strand during transcription.
Of course, identifying genes by looking for ORFs is an oversimplification; to find a bona fide gene, you may need to search for promoters and (in the case of eukaryotes) identify introns. However, using ORFs to identify putative genes is a useful approximation in prokaryotes and viruses, whose genomes are less complicated than eukaryotic genomes.
An ORF begins with a start codon and ends either at a stop codon or at the end of the string. We will assume the standard genetic code for translating an RNA string into a protein string (i.e., see the standard RNA codon table).
ORF finder from the SMS 2 package can be run online here.
Given: A DNA string
Return: The longest protein string that can be translated from an ORF of
AGCCATGTAGCTAACTCAGGTTACATGGGGATGACCCCGCGACTTGGATTAGAGTCTCTTTTGGAATAAGCCTGAATGATCCGAGTAGCATCTCAG
MLLGSFRLIPKETLIQVAGSSPCNLS
Programming Shortcut
We can also find ORFs using the EMBOSS program
getorf. It can be downloaded and run locally. The documentation can be found here. To find ORFs using Biopython, it may be useful to recall thetranslate()andreverse_complement()methods from theBio.Seqmodule.